A great view of how CenturyLink Cloud division talks to the 8 characteristics of a DevOps organization. I like some of the points they added to what we have already been discussing. I especially like the VP roles 😉 — but seriously, point 8 is key.
How does CenturyLink Cloud Division do DevOps
- Simple reporting structure. Pretty much everyone is one step away from our executive leadership. We avoid complicated fiefdoms that introduce friction and foster siloed thinking. How are we arranged? Something like this:
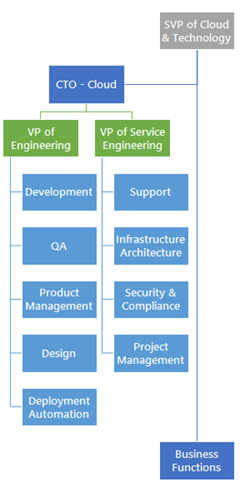
Business functions like marketing and finance are part of this structure as well. Obviously as teams continue to grow, they get carved up into disciplines, but the hierarchy remains as simplistic as possible. - Few managers, all leaders. This builds on the above point. We don’t really have any pure “managers” in the cloud organization. Sure, there are people with direct reports. But that person’s job goes well beyond people management. Rather, everyone on EVERY team is empowered to act in the best interest of our product/service. Teams have leaders who keep the team focused while being a well-informed representative to the broader organization. “Managers” are encouraged to build organizations to control, while “leaders” are encouraged to solve problems and pursue efficiency.
- Development and Operations orgs are partners. This is probably the most important characteristic I see in our division. The leaders of Engineering (that contains development) and Service Engineering (that contains operations) are close collaborators who set an example for teamwork. There’s no “us versus them” tolerated, and issues that come up between the teams – and of course they do – are resolved quickly and decisively. Each VP knows the top priorities and pain points of the other. There’s legitimate empathy between the leaders and organizations.
- Teams are co-located. Our Cloud Development Center in Bellevue is the cloud headquarters. A majority of our Engineering resources not only work there, but physically sit together in big rooms with long tables. One of our developers can easily hit a support engineer with a Nerf bullet. Co-location makes our daily standups easier, problem resolution simpler, and builds camaraderie among the various teams that build and support our global cloud. Now, there are folks distributed around the globe that are part of this Engineering team. I’m remote (most of the time) and many of our 24×7 support engineers reside in different time zones. How do we make sure distributed team members still feel involved? Tools like Slack make a HUGE difference, and regular standups and meetups make a big difference.
- Everyone looks for automation opportunities. No one in this division likes doing things manually. We wear custom t-shirts that say “Run by Robots” for crying out loud! It’s in our DNA to automate everything. You cannot scale if you do not automate. Our support engineers use our API to create tools for themselves, developers have done an excellent job maturing our continuous integration and continuous delivery capability, and even product management builds things to streamline data analysis.
- All teams responsible for the service. Our Operations staff is not responsible for keeping our service online. Wait, what? Our whole cloud organization is responsible for keeping our service healthy and meeting business need. There’s very little “that’s not MY problem” in this division. Sure, our expert support folks are the ones doing 24×7 monitoring and optimization, but developers wear pagers and get the same notifications if there’s a blip or outage. Anyone experiencing an issue with the platform – whether it’s me doing a demo, or a finance person pulling reports – is expected to notify our NOC. We’re all measured on the success of our service. Our VP of Engineering doesn’t get a bonus for shipping code that doesn’t work in production, and our VP of Service Engineering doesn’t get kudos if he maintains 100% uptime by disallowing new features. Everyone buys into the mission of building a differentiating, feature-rich product with exceptional uptime and support. And everyone is measured by that criteria.
- Knowledge resides in team and lightweight documentation. I came from a company where I wrote beautiful design documentation that is probably never going to be looked at again. By having long-lived teams built around a product/service, the “knowledge base” is the team! People know how things work and how to handle problems because they’ve been working together with the same service for a long time. At the same time, we also maintain a documented public (and internal) Knowledge Base where processes, best practices, and exceptions are noted. Each internal KB article is simple and to the point. No fluff. What do I need to know? Anyone on the team can contribute to the Knowledge Base, and it’s teeming with super useful stuff that is actively used and kept up to date. How refreshing!
- We’re not perfect, or finished! There’s so much more we can do. Continuous improvement is never done. There are things we still have to get automated, further barriers to break down between team handoffs, and more. As our team grows, other problems will inevitably surface. What matters is our culture and how we approach these problems. Is it an excuse to build up a silo or blame others? Or is it an opportunity to revisit existing procedures and make them better?

DevOps can mean a lot of things to a lot of people, but if you don’t have the organizational culture set up, it’s only a superficial implementation.